

深入解析CLIP ViT-B/32模型及其在不同设备上的加载方法详解
你有没有想过,为什么我们可以用文字描述一张图片的内容,甚至使用文字来搜索图片呢?这是因为有一种非常强大的技术,叫做CLIP ViT-B/32模型。在这篇文章中,我们将深入解析这个模型,并且向你介绍如何在不同设备上加载使用它。
为什么CLIP ViT-B/32模型那么重要?
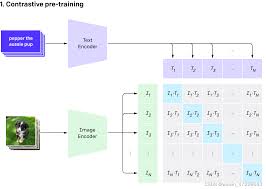
让我们先从介绍这个模型的背景开始。CLIP(Contrastive Language-Image Pretraining)是由OpenAI开发的,用于将图像和文字映射到一个共享的向量空间。通过这种方法,我们可以做很多很酷的事情,比如图像搜索、零样本图像分类等等。
其中,ViT-B/32是CLIP模型的一个变体,使用视觉变压器(Vision Transformer)作为图像编码器,在很多应用场景中表现出色。因为它强大的功能和广泛的适用性,了解如何正确加载和使用这个模型就变得尤为重要。

如何加载CLIP ViT-B/32模型
接下来,我们将一步步讲解如何在不同设备上加载和使用CLIP ViT-B/32模型。
在本地计算机上加载
- 首先,你需要安装相关的包。打开终端,运行以下命令:
- 接着,使用以下代码加载模型:
import openai.clip as clip model, preprocess = clip.load('ViT-B/32', device='cpu') - 就这样,你就可以在本地使用CLIP模型了。
pip install openai
在云服务器上加载
- 确保你已经配置好云服务器的环境,比如AWS或Google Cloud。
- 安装必要的依赖包:
pip install openai - 使用类似的代码加载模型,不同之处在于可能需要指定设备为‘cuda’以利用GPU加速:
import openai.clip as clip model, preprocess = clip.load('ViT-B/32', device='cuda') - 现在你可以在云服务器上进行大规模数据处理了。
在移动设备上加载
- 由于移动设备的算力较弱,建议使用轻量化版本的模型。
- 安装必要依赖包,并确保移动设备可以连接到网络以下载模型数据。
pip install torchlite - 使用以下代码加载模型:
from torchlite import load_model model, preprocess = load_model('ViT-B/32', device='cpu') - 你现在就可以在移动设备上进行图片和文字的处理工作了。
小技巧与建议
小技巧1:优化模型加载速度
在使用CLIP ViT-B/32模型时,提前将模型下载并缓存可以显著提高加载速度。
小技巧2:利用GPU进行加速
如果你的设备有GPU,强烈建议在代码中指定设备为‘cuda’,以充分利用GPU的计算能力。
小技巧3:定期更新模型
确保你使用的是模型的最新版本,这样可以利用最新的研究成果和优化。
常见问题解答
问题1:为什么我的模型加载很慢?
模型加载慢可能是因为网络下载速度慢,确保你有一个稳定的网络环境,或者提前缓存模型文件。
问题2:为什么GPU加载时出现错误?
请确保你的pytorch和CUDA版本匹配,并且正确安装了CUDA驱动。
问题3:是否可以在不支持CUDA的设备上使用CLIP模型?
当然可以,只需在加载模型时将设备指定为‘cpu’即可。
总结与下一步行动
通过这篇文章,我们深入解析了CLIP ViT-B/32模型,并详细介绍了在不同设备上的加载方法。这个强大的工具能让我们在图像和文本之间无缝切换,开启许多新的应用场景。无论你是研究人员还是开发者,掌握这个模型将大大提升你的工作效率。
下一步,你可以尝试在自己的项目中加载并使用这个模型,体验它的强大功能。如果你遇到任何问题,欢迎在评论区留言,我们将尽力帮助你解决。