

比较 GPT-4 8k 和 32k 模型:性能差异及应用场景分析
在这篇文章中,我们将详细比较GPT-4 8k和GPT-4 32k模型的性能差异,并探讨它们在不同应用场景中的表现。如果你正考虑选择这两种模型之一,那么这篇文章将为你提供清晰的见解。
主题的重要性和必要性
随着人工智能的发展,聊天机器人和语言模型已成为我们生活和工作中不可或缺的一部分。GPT-4,作为OpenAI推出的最新语言模型,其8k和32k版本在性能和应用方面有显著差异。了解这些差异有助于我们在具体需求中选择最合适的模型,这不仅能提高工作效率,还能节省成本。
预期内容概述
本文将从以下几个方面详细阐述GPT-4 8k和32k模型的差异:
- 模型性能
- 应用场景
- 实际使用中的优势和劣势
- 常见问题解答
通过这些分析,我们希望能帮助读者更好地理解和选择适合自己的GPT-4模型。
GPT-4 8k与32k模型的性能差异
上下文窗口尺寸的影响
GPT-4 8k和GPT-4 32k模型的最大区别在于它们的上下文窗口大小。简单来说,8k模型可以处理最多8,000个tokens的文本,而32k模型可以处理多达32,000个tokens的文本。这意味着32k模型能够处理更长的对话和文本内容,而不会丢失上下文信息。
性能对比
从性能角度来看,GPT-4 32k在处理复杂任务和长文本时具有明显优势。它不仅能够记住和处理更多的信息,还能生成更长和更连贯的回复。然而,这种性能提升也伴随着更高的计算资源需求和成本。
计算资源和成本
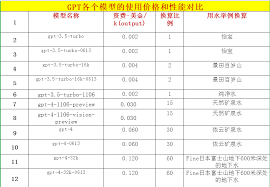
使用GPT-4 32k模型需要更多的计算资源,这直接导致了更高的使用成本。根据OpenAI的定价策略,32k模型在每1,000个输入tokens的价格约为0.06美元,而每1,000个输出tokens的价格约为0.12美元。相比之下,8k模型的价格更加低廉。
- GPT-4 8k:$0.03/1K输入tokens,$0.06/1K输出tokens
- GPT-4 32k:$0.06/1K输入tokens,$0.12/1K输出tokens
应用场景分析
适用场景
根据上下文窗口大小和性能差异,GPT-4 8k和GPT-4 32k模型在不同的应用场景中表现各有千秋:
- 8k模型:适合用于短文本生成、简要问答、产品描述等不需要大量上下文的场景。
- 32k模型:适合处理长文本、复杂对话、技术文档撰写等需要大量上下文的场景。

小技巧和实用建议
规划和优化预算
在选择GPT-4模型时,预算是一个关键考虑因素。如果你的项目不需要处理非常长的文本,可以选择成本较低的8k模型。这样可以在保证性能的前提下,最大化地节省成本。
根据任务选择合适的上下文窗口
评估任务需求,选择适合的上下文窗口。如果需要处理技术文档或进行深入的对话,32k模型更为适合。而对于一般的文本生成或问答任务,8k模型已经足够。
利用总结功能提高效率
对于长文本,可以将其分段提交给模型进行总结,获得关键要点,从而提高信息处理效率。这种方法尤其适用于32k模型,能充分利用其较大的上下文窗口。
使用多模型策略
灵活使用8k和32k模型,根据具体需求进行转换。例如,对于初期的文本分析和整理,可以先使用8k模型;而对于最终的复杂内容生成,可以转而使用32k模型。
持续监控和优化
在使用过程中,持续监控模型的表现,依据反馈不断优化使用策略,确保在不同场景下都能获得最佳效果。
常见问题解答
1. GPT-4 8k和32k具体有什么区别?
主要区别在于上下文窗口的大小。8k可以处理最多8,000个tokens,而32k可以处理多达32,000个tokens。因此,32k能处理更长的文本和对话。
2. 选择哪种模型更合适?
这取决于你的具体需求。如果需要处理长文本或复杂对话,选择32k模型。如果只是进行一般的文本生成或问答,8k模型已经足够。
3. 使用32k模型的成本如何?
使用32k模型的计算资源需求更高,成本也相对更高。具体费用可以参考OpenAI的定价策略,32k模型的价格是8k模型的两倍左右。
4. 是否可以同时使用8k和32k模型?
是的,许多项目可以根据需求灵活切换使用这两种模型。例如,初期数据分析使用8k模型,最终内容生成使用32k模型。
5. GPT-4模型的应用前景如何?
GPT-4在多领域都有广泛的应用前景,包括但不限于文本生成、客户服务、技术文档撰写等。特别是32k模型,在处理需要大量上下文的任务时表现非常优异。
总结与行动建议
通过本文的详细比较,我们可以看到GPT-4 8k和GPT-4 32k模型各有优劣。在具体选择时,需要根据自己的具体需求,权衡成本和性能,选择最合适的模型来满足工作需求。如果你对这两种模型还有更多疑问,建议先小规模测试,然后根据实际表现做出最终决定。
下一步,你可以访问OpenAI官网,详细了解两种模型的定价和使用指南,制定更优化的AI应用策略。